Eval
Blueprint-Bench 2
How do AI agents understand space? We test this by asking them to convert apartment photographs into accurate 2D floor plans. While photos are familiar training data, spatial reconstruction requires genuine intelligence.
Blueprint-Bench 2 tests spatial reasoning by asking AI agents to convert apartment photographs into accurate 2D floor plans. Each agent processes 50 apartments sequentially, examining ~20 interior photos per apartment and generating a floor plan showing room layouts, connections, and relative sizes. Agents use a persistent notepad to carry insights between apartments, enabling cross-apartment learning and iterative strategy refinement.
Connectivity similarity score
All scores are normalized so that the random baseline maps to 0 and a perfect score maps to 1. Error bars represent standard error.
Leaderboard
| Model | Score | |
|---|---|---|
| 1 | Human* | 0.586 |
| 2 |  GPT 5.5 GPT 5.5 | 0.362 |
| 3 |  Gemini 3.1 Pro Gemini 3.1 Pro | 0.265 |
| 4 |  Claude Opus 4.7 Claude Opus 4.7 | 0.245 |
| 5 |  Kimi K2.6 Kimi K2.6 | 0.039 |
| 6 | Gemini 3 Flash | 0.000** |
| 7 |  Grok 4.3 Grok 4.3 | 0.000** |
| 8 | Gemini Robotics-ER 1.6 | 0.000** |
| 9 | Claude Haiku 4.5 | 0.000** |
| 10 | Grok 4.20 Reasoning | 0.000** |
**Score at or below the random baseline
*Human baseline tested on subset of 12 apartments only
The eval
Blueprint-Bench 2 tests spatial reasoning through converting apartment photographs into accurate 2D floor plans. Models examine ~20 interior photos and generate a floor plan showing room layouts, connections, and relative sizes.
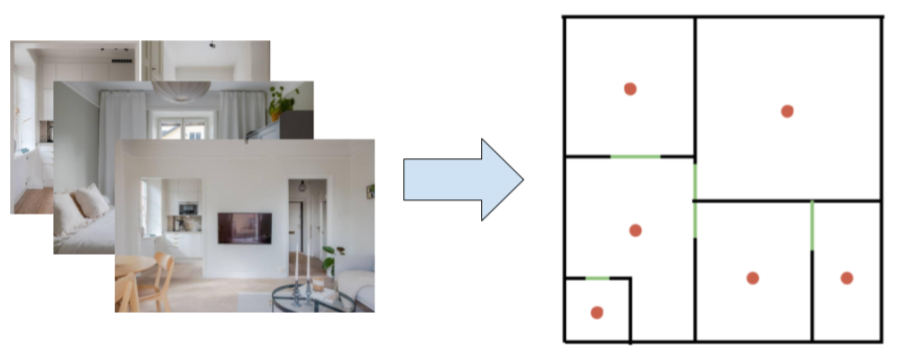
Converting apartment photographs (left) into a 2D floor plan (right). Red dots indicate rooms, green lines show doorways.
Success requires identifying rooms, inferring spatial relationships, understanding scale, and generating structured output following strict formatting rules.
Scoring
Plans are scored by comparing their connectivity graph against ground truth. The composite score weights six sub-metrics: Jaccard similarity (50%) measures overlap in room-to-room connections, degree similarity (20%) compares how many doors each room has, density similarity (10%) checks overall graph connectivity, room count (10%), door count (5%), and orientation (5%). All scores are matched under D4 symmetry to be rotation and reflection invariant. Scores are then normalized so that the random baseline maps to 0 and a perfect score maps to 1.
Agent notepad system
Each agent processes 50 apartments sequentially and has access to a persistent notepad. This notepad carries across apartments, letting agents record strategies, common patterns, and lessons learned. The best models use this to build structured knowledge about typical apartment layouts, improving their approach over time.
Key findings
Blueprint-Bench 2 was released in May 2026. The top three models (GPT 5.5, Gemini 3.1 Pro, and Claude Opus 4.7) significantly outperform the rest, with tight variance indicating consistent spatial reasoning. The key discriminator is Jaccard similarity (room-to-room connectivity). All models achieve ~90% on room count, but lower-performing models struggle to correctly infer which rooms connect to which.
Gemini Robotics-ER 1.6 underperforms expectations. Despite being designed for spatial and embodied reasoning, it scores below Gemini 3 Flash. Its spatial specialization does not translate to improved floor plan generation.
Sparks of spatial reasoning
In the original Blueprint-Bench, model outputs were essentially noise. In Blueprint-Bench 2, we see the first signs of genuine spatial reasoning from 2D photographs.
Reversing camera direction using landmarks - Gemini 3.1 Pro uses a washer/dryer visible in two photos to figure out which direction the camera is facing:


Inferring a through-room from multiple doorways - GPT 5.5 notices doors in two photos of the same bedroom lead to different rooms, deducing it functions as a connecting passage:


Are you a researcher and want to test a model on Blueprint-Bench?
Contact us at research@andonlabs.com.