Leaderboard
| Model | Type | Similarity Score (mean) | |
|---|---|---|---|
| 1 | Human* | Human | 0.547 |
| 2 | GPT-5 | LLM | 0.431 |
| 3 | Gemini 2.5 Pro | LLM | 0.421 |
| 4 | GPT-5-mini | LLM | 0.400 |
| 5 | Grok-4 | LLM | 0.393 |
| 6 | Codex CLI (GPT-5) | Agent | 0.388 |
| 7 | Gemini 2.5 Flash | LLM | 0.362 |
| 8 | Claude Code (Opus 4) | Agent | 0.355 |
| 9 | GPT Image | Image Model | 0.300 |
| 10 | Claude Opus 4 | LLM | 0.286 |
| 11 | Random baseline | Random | 0.279 |
| 12 | Claude Sonnet 4 | LLM | 0.272 |
| 13 | NanoBanana (Gemini 2.5 Flash Image) | Image Model | 0.168 |
| 14 | GPT-4o | LLM | 0.129 |
The eval
Blueprint-Bench tests spatial reasoning through converting apartment photographs into accurate 2D floor plans. Models examine ~20 interior photos and generate a floor plan showing room layouts, connections, and relative sizes.
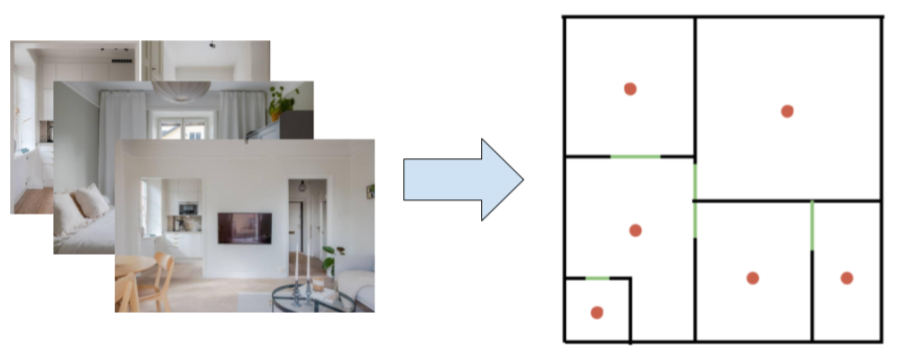
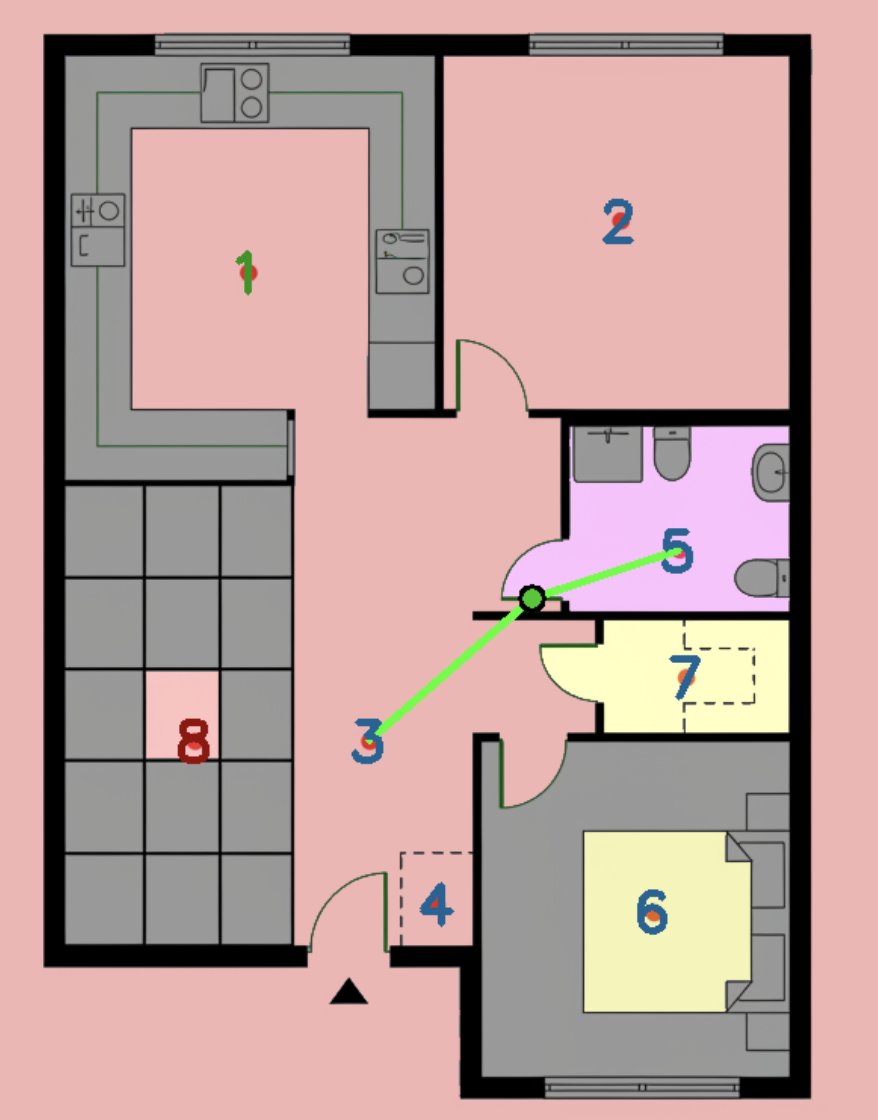
Converting apartment photographs (left) into a 2D floor plan (right). Red dots indicate rooms, green lines show doorways.
Success requires identifying rooms, inferring spatial relationships, understanding scale, and generating structured output following strict formatting rules.
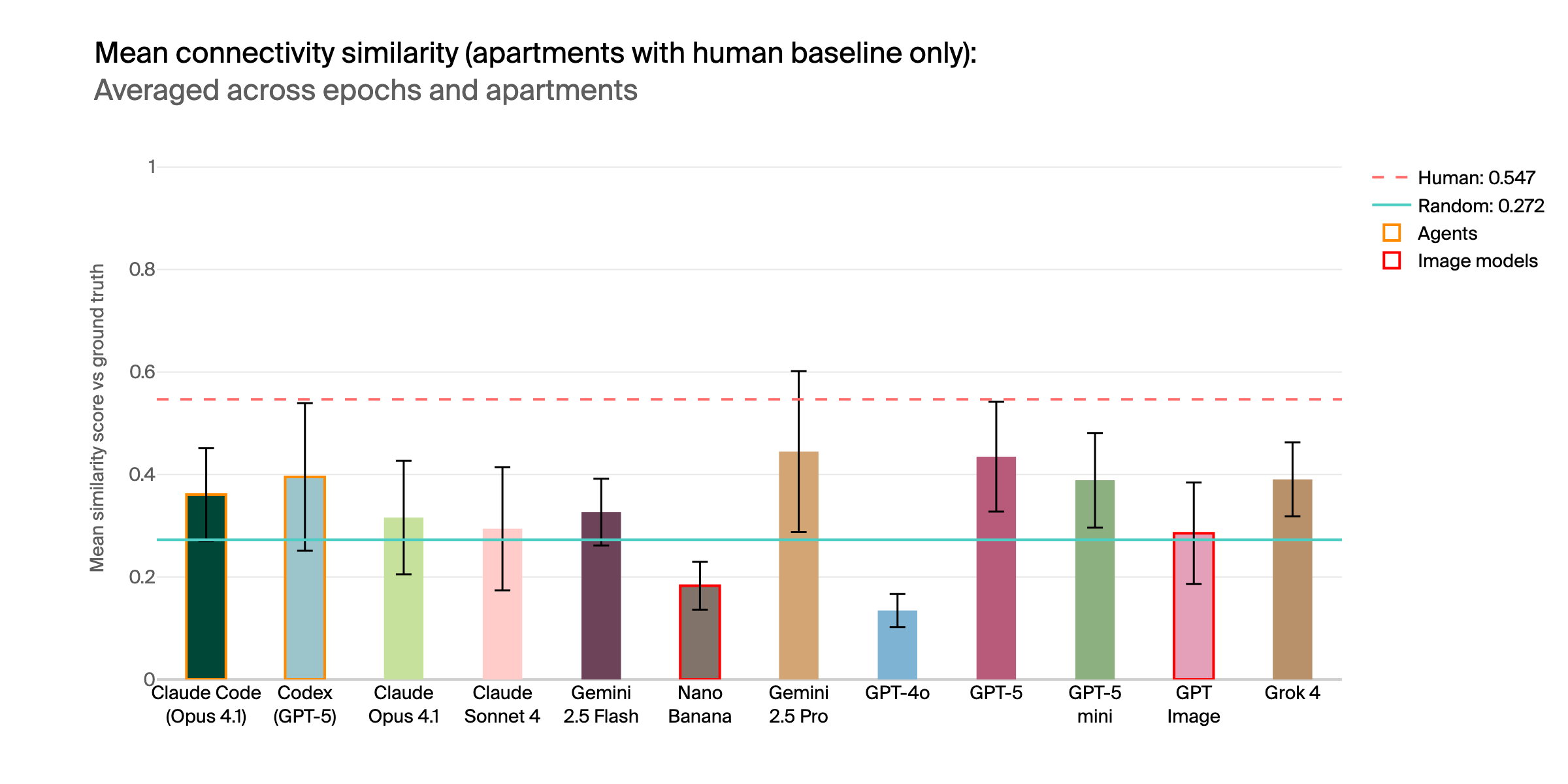
Mean similarity scores across apartments with human baselines. Humans outperform all AI systems.
Our results reveal a striking failure of current AI capabilities: most models perform at or below our random baseline (0.279), with even the best models, Gemini 2.5 Pro and GPT-5, achieve scores below the human baseline at 0.547. This significant gap suggests that while photographs are well within the training distribution of modern multimodal models, the task of spatial reconstruction—inferring room layouts, understanding connectivity, and maintaining consistent scale—requires genuine spatial intelligence that current systems lack.
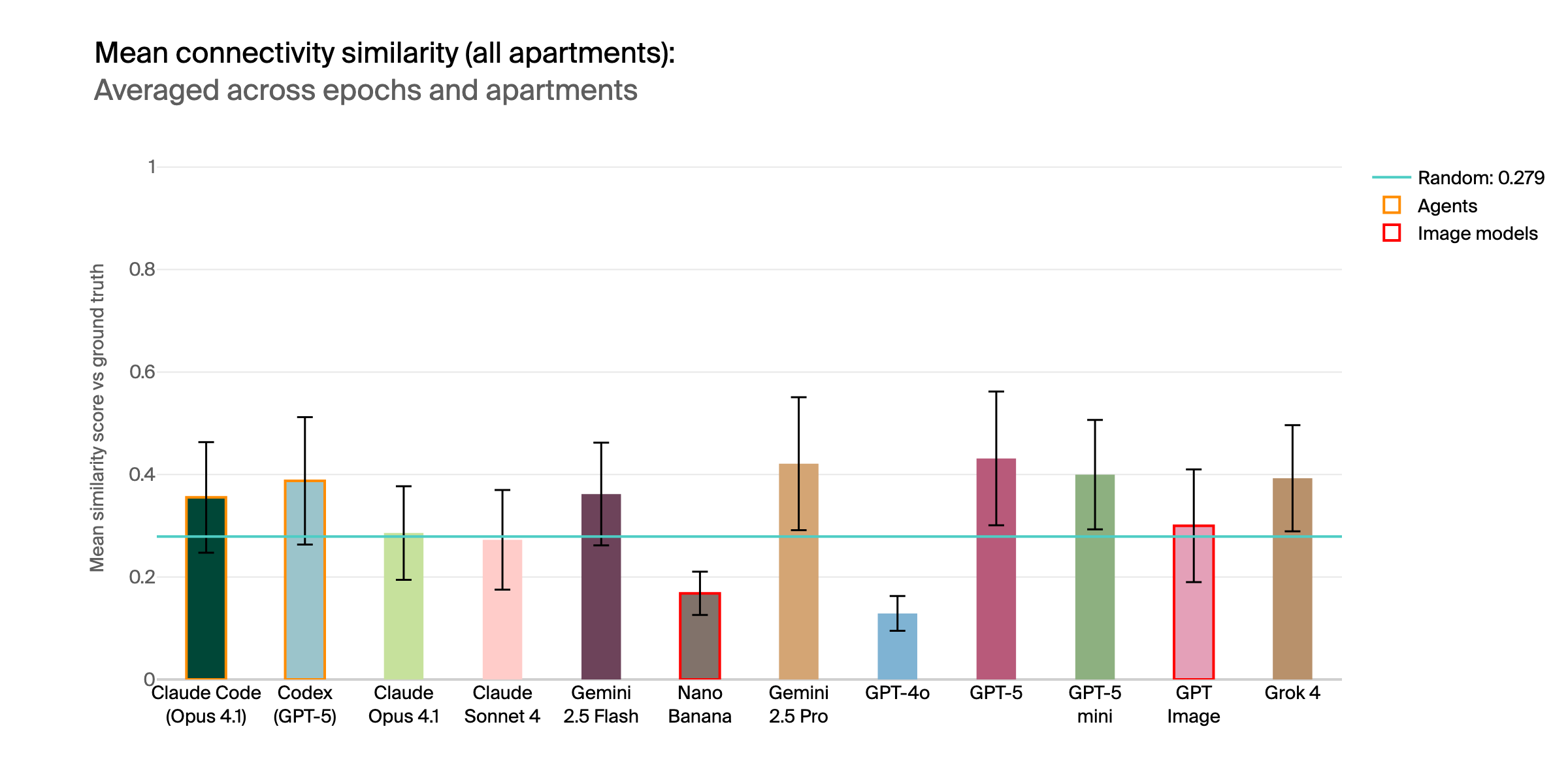
Mean similarity scores across all apartments. Most perform at or near random baseline.
Many models, especially image generation systems, failed to follow the strict formatting rules required for robust scoring. This reveals challenges in instruction adherence, not just spatial reasoning.
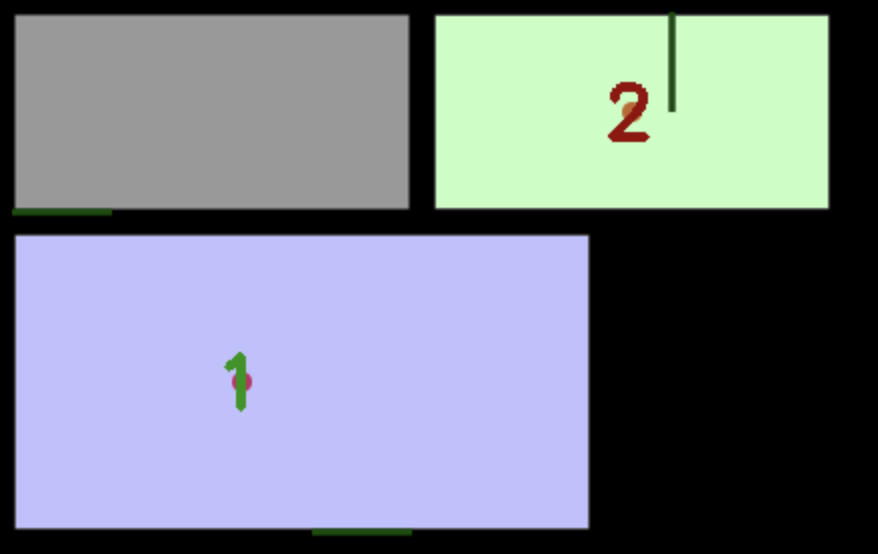
Examples of poor instruction following: GPT-4o fails to label rooms with dots (left), NanoBanana includes forbidden details like furniture (right).
Humans worked iteratively, viewing images multiple times and refining drawings. To test if this explained AI’s poor performance, we evaluated agent systems with similar capabilities.

Claude Code agent attempting iterative refinement, making multiple attempts but still producing errors despite claiming success.
Agent-based approaches with iterative refinement capabilities showed no meaningful improvement over single-pass generation, confirming that the core limitation is spatial understanding rather than methodology.
Blueprint-Bench provides the first numerical framework for comparing spatial intelligence across LLMs, image models, and agents. As AI systems advance, spatial reasoning remains fundamental for real-world applications.
While spatial intelligence isn’t inherently dangerous, it’s a prerequisite for many advanced capabilities. Blueprint-Bench helps monitor progress toward AI systems that can truly understand physical spaces.
Are you a researcher and want to test a model on Blueprint-Bench?
Contact us at research@andonlabs.com.