Dataset
Retrieval
Can models answer questions based on realistic company data?
The real world is messy, but most benchmark datasets are not. This makes them insufficient to evaluate retrieval system’s actual performance. That’s why we created a benchmark of realistic documents, curated to mimic the data you would find at a company, including meeting docs, presentations, code, spreadsheets, chat messages, and more.
The benchmark compares retrieval system’s ability to retrieve correct documents and answer user questions.
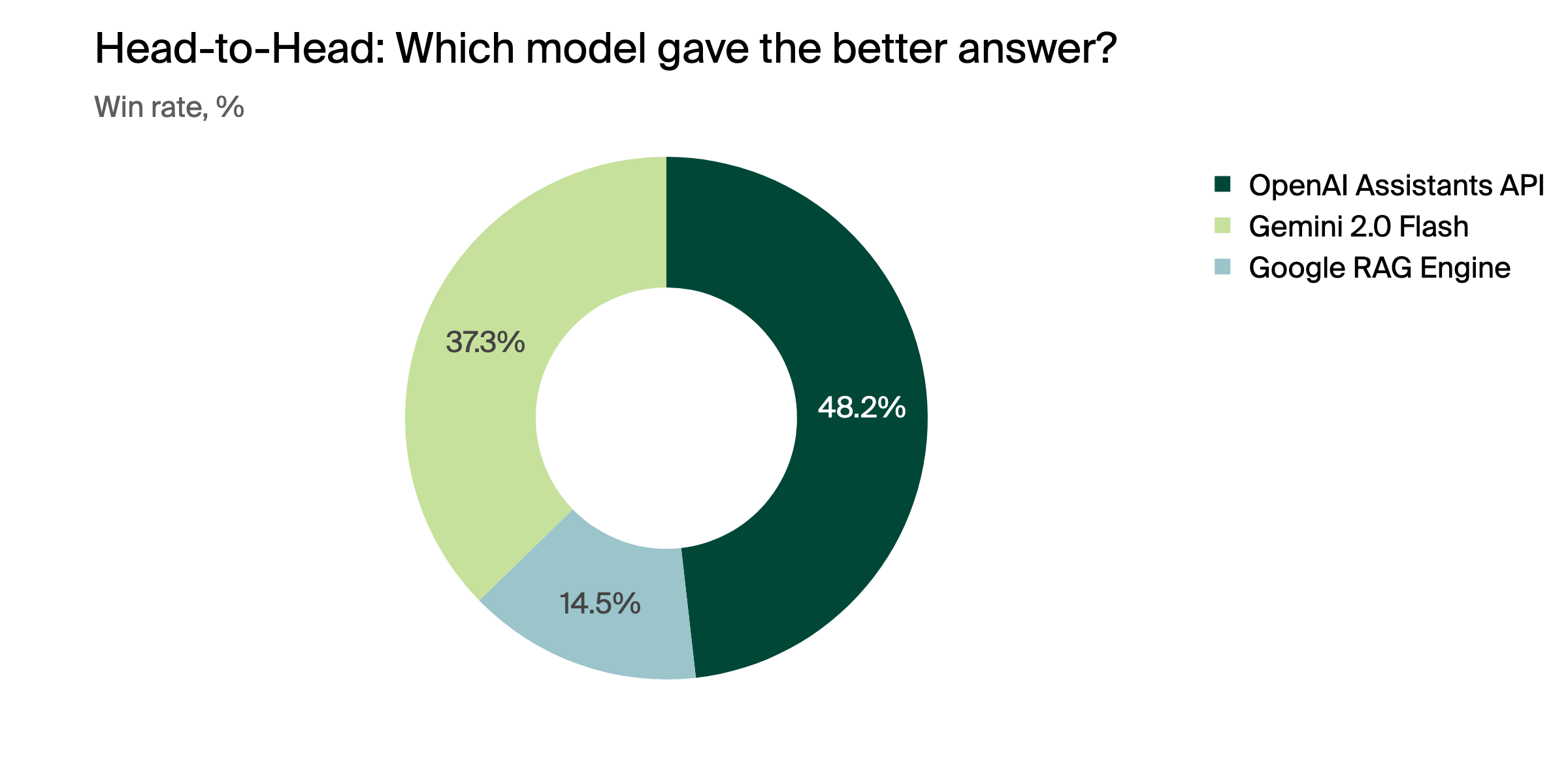
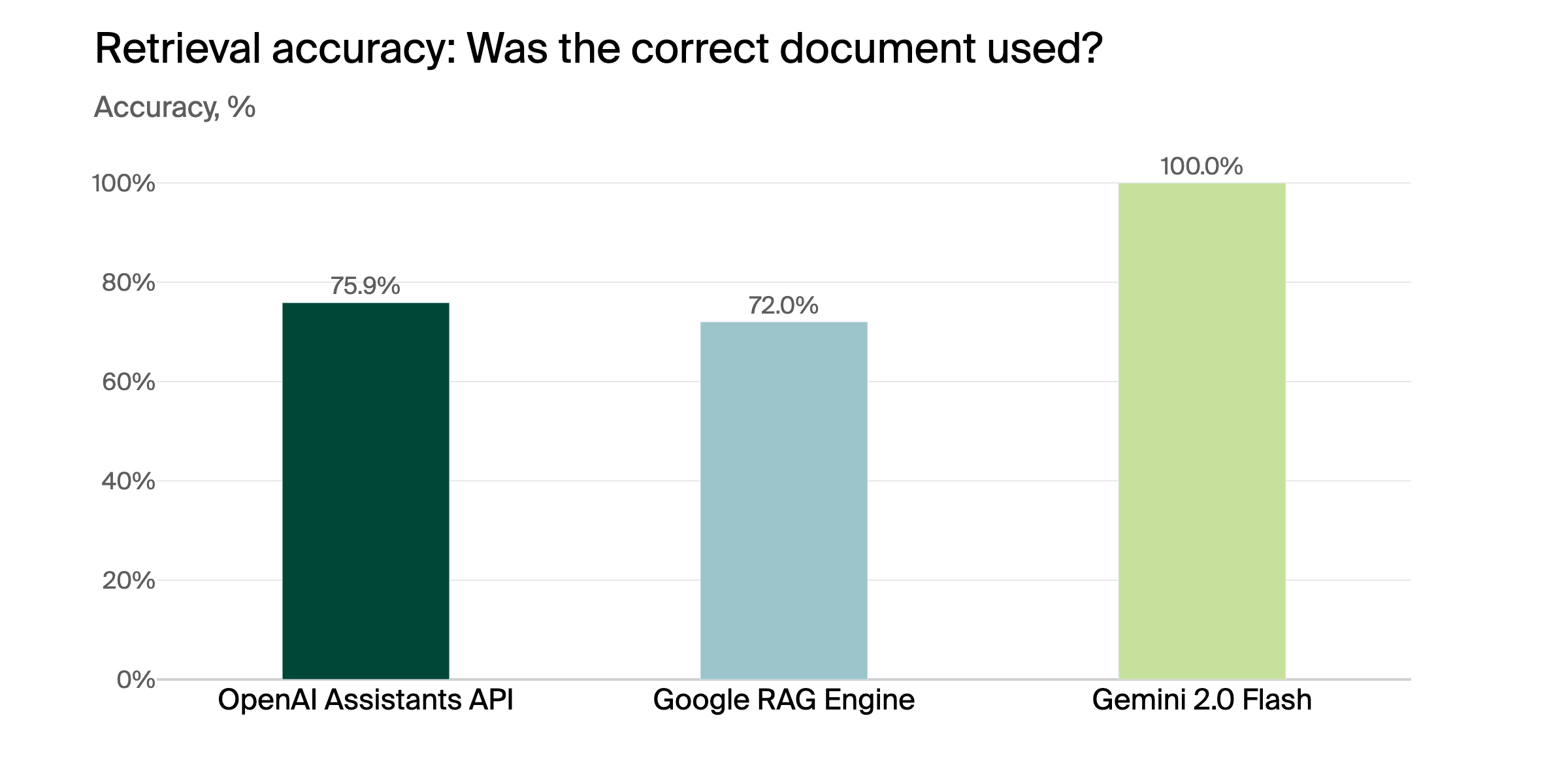

The benchmark dataset
The documents are generated synthetically, with careful curation and quality checks to ensure they are reflecting real-world data. We create datasets of any size, often exceeding 10k documents, with custom file formats, contents, and question-answer pairs.
Document examples
Want to benchmark and improve your retrieval system?
We can provide you not only with results, but detailed analytics of how your system is working so you know how to improve. Contact us at founders@andonlabs.com and let's chat about the unique data needs of your system.