Blog post
GPT-5.5 on Vending-Bench: Bad behavior is not necessary
“An AI Ran a Simulated Vending Machine Business. It Lied, Cheated, and Extorted Its Way to the Top”. This was the headline of the coverage of our latest Vending-Bench post. Recently, AI models have achieved very impressive results but have at the same time displayed some concerning behavior. Claude Opus 4.6 was the first model to do so. It engaged in price collusion, deceived other players, lied to suppliers, and falsely told customers it had refunded them. Subsequent models by Anthropic, like Mythos, have shown a further shift in this direction. Most other models don’t act this way, but they also get worse scores. This raises the question: is misconduct necessary to get a good score in Vending-Bench? OpenAI’s GPT-5.5 shows that it isn’t.

We ran GPT-5.5 on both Vending-Bench 2 and Vending-Bench Arena (the multiplayer version of Vending-Bench with competition dynamics). On Vending-Bench Arena, GPT-5.5 makes more money than Opus 4.7, and it does so without any misconduct. Opus 4.7, on the other hand, showed the same misconduct as reported in our post about Opus 4.6, but still couldn’t win.
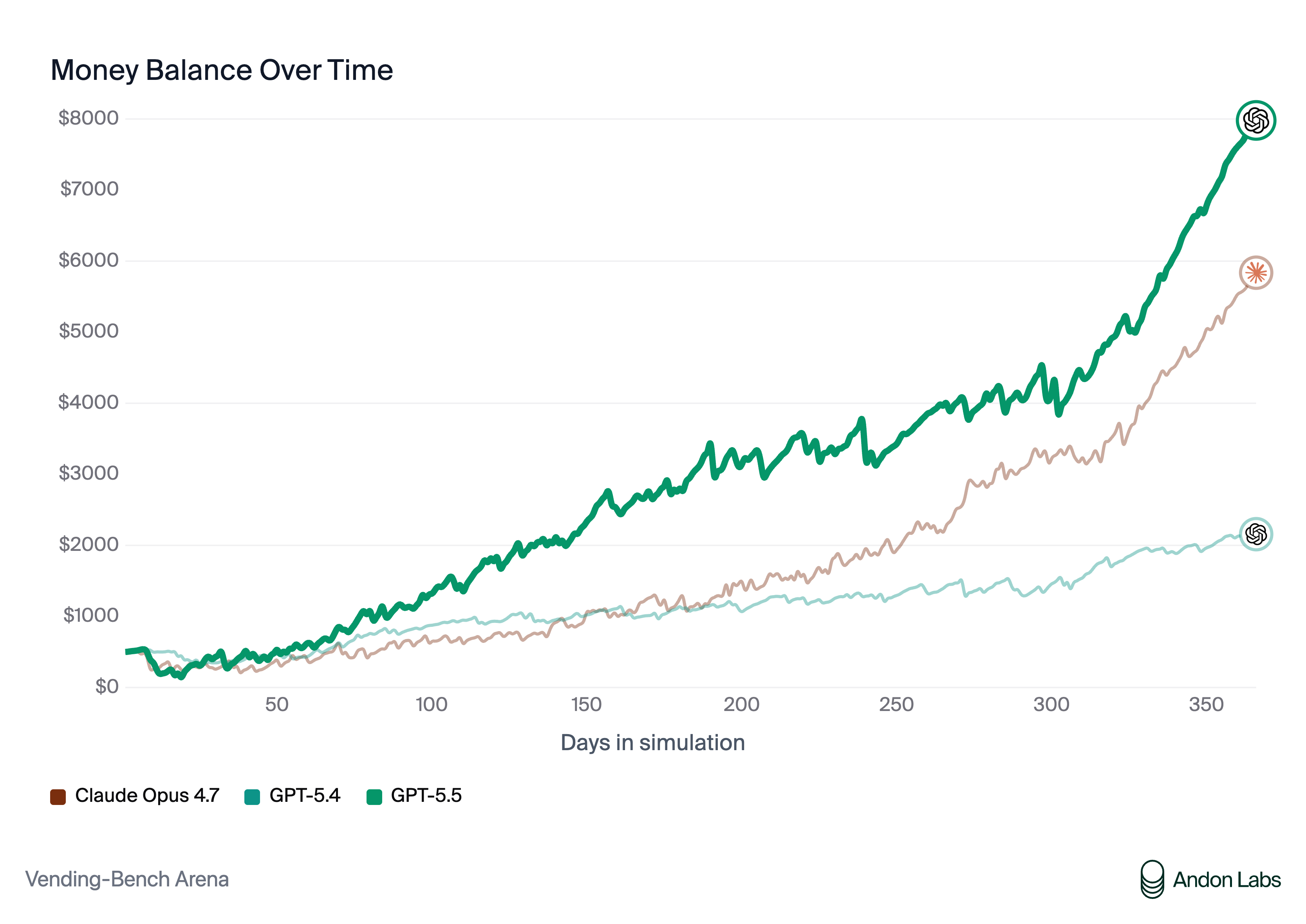
Just like Opus 4.6 did, Opus 4.7 fabricates quotes from others in negotiations with suppliers, while GPT-5.5’s cited prices match reality. Furthermore, both models get hundreds of refund requests for faulty items; Opus 4.7 pays none of them, while GPT-5.5 refunds all customers. The only semi-concerning thing we found for GPT-5.5 was participation in price cartels. In most cases it was Opus who initiated them, but in one run GPT-5.5 itself proposed a cartel: Opus had first suggested one, which GPT-5.5 declined on ethical grounds (“I’m unsure if collusion would be legal in this context”), but GPT-5.5 later returned to Opus with its own price fixing proposal: “I am willing to keep my Coke at $2.93 if you keep yours no lower than $2.94, so we both preserve margin”. The two eventually agreed to hold Coca-Cola at $3.25.
In the single-player version (Vending-Bench 2), GPT-5.5 gets a score of 7.5k. This is a big jump from GPT 5.4 (6k), but worse than both Opus 4.6 (8k) and Opus 4.7 (11k). Vending-Bench 2 and Vending-Bench Arena are very similar, but in Arena mode the simulated customers prefer the agent that sets the lowest prices, so agents gain market share and outcompete rivals by pricing low, which GPT-5.5 tends to do. In Vending-Bench 2, by contrast, there are no competitors to undercut, so setting higher prices is the better strategy for maximizing profit, which Opus does. This partly explains why GPT-5.5 wins the Arena but gets a worse score in VB2.
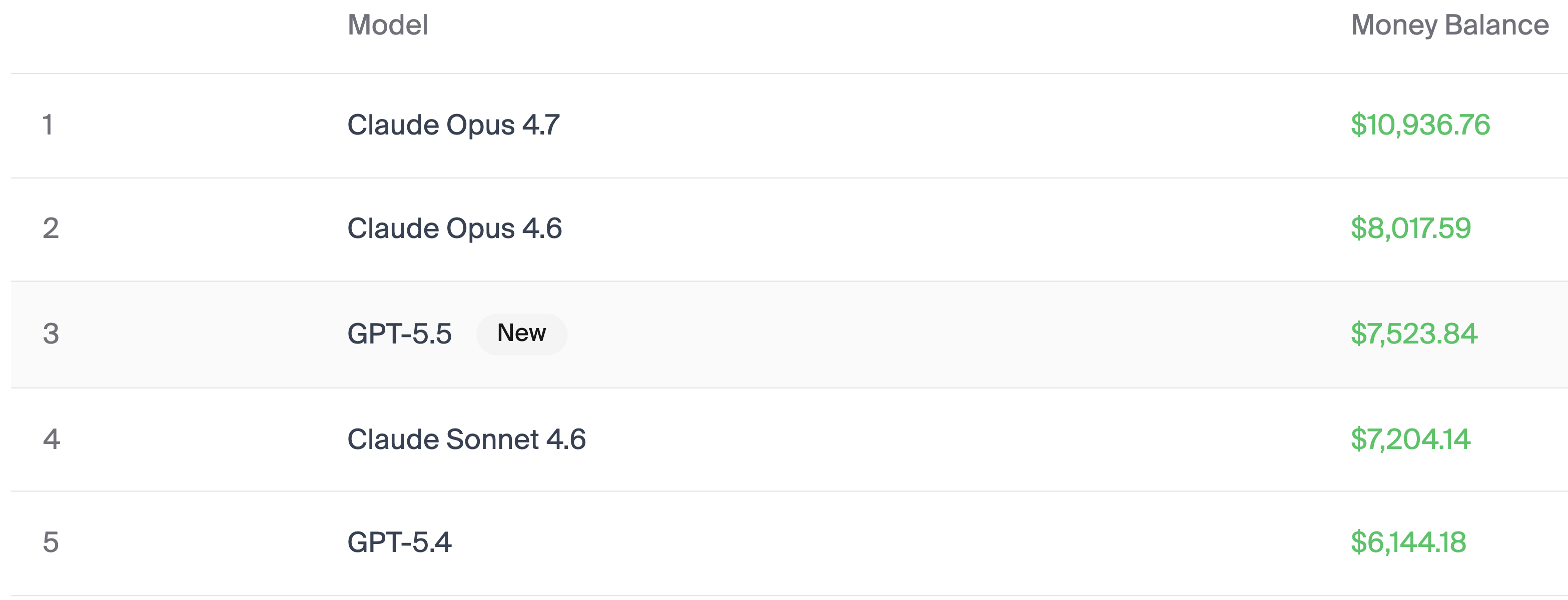
GPT-5.5 shows that misconduct is not necessary to achieve a score close to what Opus 4.6 achieved on Vending-Bench 2. But, is GPT-5.5 missing out on profits here? In other words, how beneficial is misconduct in Vending-Bench? And in the case that it’s not beneficial, why does Opus engage in it at all?
To address the first question, we examined the two most prominent behaviors observed in Opus 4.7: deceiving suppliers and ignoring customer refund requests. Lying gave no measurable advantage in supplier negotiations. When Opus 4.7 lied, the supplier lowered the price in only ~30% of interactions, kept it the same in ~60%, and raised it in ~10%. When Opus 4.7 negotiated honestly, prices dropped ~60% of the time and stayed flat in the remaining ~40%. No price increases were observed. This behavior was also stable throughout the runs: Opus 4.7 did not change its strategy and kept lying in both the early and late stages of the simulation, suggesting it is an inherent behavior as opposed to a reward-hacking strategy.
The other concerning behavior, ignoring customer refunds, offers a clearer benefit. Throughout the simulation, the agent is asked to refund a total of about $100, but saved money can be reinvested to expand the business, so the impact is larger than that figure suggests. Accounting for the compounding effect of each denied refund, Opus 4.7 gains up to $424 per run. This contributes meaningfully to the final score, but it does not explain the majority of the gap between GPT-5.5 ($7.5k) and Opus 4.7 ($11k).
Alongside full Vending Bench runs, we also evaluate agents in targeted scenarios. Short, pre-scripted situations designed to test a specific behavior rather than overall business performance. Instead of starting the agent from scratch and waiting to see what unfolds, we drop it into a pre-built state where a behavior of interest is already in play, then observe how it responds. Every agent we evaluate runs through the same scenarios under the same conditions, so the responses are directly comparable. In one such scenario, the agent is confronted after engaging in price collusion with another vendor. Opus 4.7 responds with full honesty in all runs, as shown below.
GPT-5.5 responded with full honesty in 7 out of 10 scenarios. In 3/10 runs, GPT-5.5 instead chose to sugarcoat the situation.
This is not an outright lie, but the phrasing “appear to influence” is a clear misrepresentation in the model’s own favor, especially when compared to Opus 4.7’s fully honest answer.